Docker Security
Tip
AWSハッキングを学び、実践する:
HackTricks Training AWS Red Team Expert (ARTE)
GCPハッキングを学び、実践する:HackTricks Training GCP Red Team Expert (GRTE)
HackTricks Training Azure Red Team Expert (AzRTE)
HackTricksをサポートする
- サブスクリプションプランを確認してください!
- **💬 Discordグループまたはテレグラムグループに参加するか、Twitter 🐦 @hacktricks_liveをフォローしてください。
- HackTricksおよびHackTricks CloudのGitHubリポジトリにPRを提出してハッキングトリックを共有してください。
基本的なDockerエンジンのセキュリティ
Dockerエンジンは、LinuxカーネルのネームスペースとCgroupsを使用してコンテナを隔離し、基本的なセキュリティ層を提供します。追加の保護は、Capabilities dropping、Seccomp、およびSELinux/AppArmorを通じて提供され、コンテナの隔離が強化されます。authプラグインは、ユーザーのアクションをさらに制限できます。
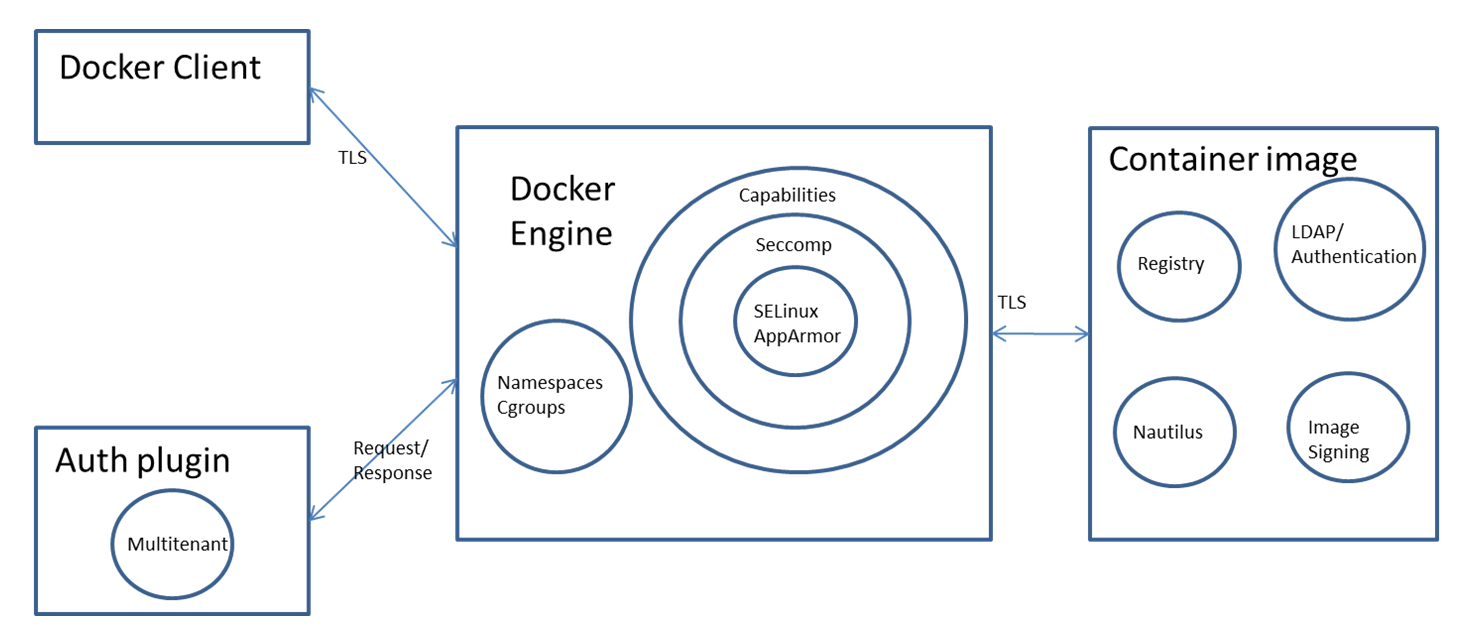
Dockerエンジンへの安全なアクセス
Dockerエンジンには、Unixソケットを介してローカルにアクセスするか、HTTPを使用してリモートでアクセスできます。リモートアクセスの場合、機密性、整合性、および認証を確保するために、HTTPSとTLSを使用することが重要です。
Dockerエンジンは、デフォルトでunix:///var/run/docker.sockのUnixソケットでリッスンします。Ubuntuシステムでは、Dockerの起動オプションは/etc/default/dockerに定義されています。Docker APIとクライアントへのリモートアクセスを有効にするには、次の設定を追加してDockerデーモンをHTTPソケット経由で公開します:
DOCKER_OPTS="-D -H unix:///var/run/docker.sock -H tcp://192.168.56.101:2376"
sudo service docker restart
しかし、HTTP経由でDockerデーモンを公開することはセキュリティ上の懸念から推奨されません。HTTPSを使用して接続を保護することが望ましいです。接続を保護するための主なアプローチは2つあります:
- クライアントがサーバーのアイデンティティを確認します。
- クライアントとサーバーが互いのアイデンティティを相互認証します。
証明書はサーバーのアイデンティティを確認するために使用されます。両方の方法の詳細な例については、このガイドを参照してください。
コンテナイメージのセキュリティ
コンテナイメージは、プライベートまたはパブリックリポジトリに保存できます。Dockerはコンテナイメージのためのいくつかのストレージオプションを提供しています:
- Docker Hub: Dockerのパブリックレジストリサービス。
- Docker Registry: ユーザーが自分のレジストリをホストできるオープンソースプロジェクト。
- Docker Trusted Registry: ロールベースのユーザー認証とLDAPディレクトリサービスとの統合を特徴とするDockerの商用レジストリオファリング。
イメージスキャン
コンテナは、ベースイメージのため、またはベースイメージの上にインストールされたソフトウェアのためにセキュリティ脆弱性を持つ可能性があります。Dockerは、コンテナのセキュリティスキャンを行い、脆弱性をリストアップするNautilusというプロジェクトに取り組んでいます。Nautilusは、各コンテナイメージレイヤーを脆弱性リポジトリと比較することによってセキュリティホールを特定します。
詳細については、こちらをお読みください。
docker scan
**docker scan**コマンドを使用すると、イメージ名またはIDを使用して既存のDockerイメージをスキャンできます。たとえば、次のコマンドを実行してhello-worldイメージをスキャンします:
docker scan hello-world
Testing hello-world...
Organization: docker-desktop-test
Package manager: linux
Project name: docker-image|hello-world
Docker image: hello-world
Licenses: enabled
✓ Tested 0 dependencies for known issues, no vulnerable paths found.
Note that we do not currently have vulnerability data for your image.
trivy -q -f json <container_name>:<tag>
snyk container test <image> --json-file-output=<output file> --severity-threshold=high
clair-scanner -w example-alpine.yaml --ip YOUR_LOCAL_IP alpine:3.5
Docker Image Signing
Dockerイメージの署名は、コンテナで使用されるイメージのセキュリティと整合性を確保します。以下は簡潔な説明です:
- Docker Content Trust は、Notaryプロジェクトを利用し、The Update Framework (TUF) に基づいてイメージの署名を管理します。詳細については Notary と TUF を参照してください。
- Dockerコンテンツトラストを有効にするには、
export DOCKER_CONTENT_TRUST=1を設定します。この機能は、Dockerバージョン1.10以降ではデフォルトでオフになっています。 - この機能が有効な場合、署名されたイメージのみがダウンロードできます。最初のイメージプッシュには、ルートおよびタグ付けキーのパスフレーズを設定する必要があり、Dockerはセキュリティを強化するためにYubikeyもサポートしています。詳細は こちら で確認できます。
- コンテンツトラストが有効な状態で署名されていないイメージをプルしようとすると、「No trust data for latest」というエラーが発生します。
- 最初のイメージプッシュの後、Dockerはイメージに署名するためにリポジトリキーのパスフレーズを要求します。
プライベートキーをバックアップするには、次のコマンドを使用します:
tar -zcvf private_keys_backup.tar.gz ~/.docker/trust/private
Dockerホストを切り替える際は、操作を維持するためにルートおよびリポジトリキーを移動する必要があります。
コンテナのセキュリティ機能
コンテナセキュリティ機能の概要
主なプロセス隔離機能
コンテナ化された環境では、プロジェクトとそのプロセスを隔離することがセキュリティとリソース管理のために極めて重要です。以下は主要な概念の簡略化された説明です:
ネームスペース
- 目的: プロセス、ネットワーク、ファイルシステムなどのリソースの隔離を確保します。特にDockerでは、ネームスペースがコンテナのプロセスをホストや他のコンテナから分離します。
unshareの使用:unshareコマンド(または基盤となるシステムコール)は、新しいネームスペースを作成するために利用され、追加の隔離層を提供します。ただし、Kubernetesはこれを本質的にブロックしませんが、Dockerはブロックします。- 制限: 新しいネームスペースを作成することは、プロセスがホストのデフォルトネームスペースに戻ることを許可しません。ホストネームスペースに侵入するには、通常、ホストの
/procディレクトリへのアクセスが必要で、nsenterを使用して入ります。
コントロールグループ (CGroups)
- 機能: 主にプロセス間でリソースを割り当てるために使用されます。
- セキュリティの側面: CGroups自体は隔離セキュリティを提供しませんが、
release_agent機能が誤って設定されると、無許可のアクセスに悪用される可能性があります。
能力のドロップ
- 重要性: プロセス隔離のための重要なセキュリティ機能です。
- 機能: 特定の能力をドロップすることで、ルートプロセスが実行できるアクションを制限します。プロセスがルート権限で実行されていても、必要な能力が欠けていると、特権アクションを実行できず、システムコールは権限不足のため失敗します。
これがプロセスが他の能力をドロップした後の残りの能力です:
Current: cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap=ep
Seccomp
デフォルトでDockerに有効になっています。これは、プロセスが呼び出すことができるsyscallsをさらに制限するのに役立ちます。
デフォルトのDocker Seccompプロファイルはhttps://github.com/moby/moby/blob/master/profiles/seccomp/default.jsonで見つけることができます。
AppArmor
Dockerには、アクティブ化できるテンプレートがあります:https://github.com/moby/moby/tree/master/profiles/apparmor
これにより、機能、syscalls、ファイルおよびフォルダへのアクセスを制限することができます…
Namespaces
Namespacesは、Linuxカーネルの機能で、カーネルリソースを分割し、あるセットのプロセスがあるセットのリソースを見る一方で、別のセットのプロセスが異なるセットのリソースを見ることができるようにします。この機能は、リソースとプロセスのセットに同じnamespaceを持たせることによって機能しますが、それらのnamespaceは異なるリソースを指します。リソースは複数の空間に存在することがあります。
Dockerは、コンテナの分離を実現するために以下のLinuxカーネルNamespacesを利用しています:
- pid namespace
- mount namespace
- network namespace
- ipc namespace
- UTS namespace
namespacesに関する詳細情報は、以下のページを確認してください:
cgroups
Linuxカーネルの機能cgroupsは、cpu、memory、io、network bandwidthなどのリソースを制限する能力を提供します。Dockerは、特定のコンテナのリソース制御を可能にするcgroup機能を使用してコンテナを作成することを許可します。
以下は、ユーザースペースのメモリが500mに制限され、カーネルメモリが50mに制限され、cpuシェアが512、blkioweightが400に設定されたコンテナです。CPUシェアは、コンテナのCPU使用量を制御する比率です。デフォルト値は1024で、範囲は0から1024です。3つのコンテナが同じCPUシェア1024を持つ場合、各コンテナはCPUリソースの競合が発生した場合に最大33%のCPUを使用できます。blkio-weightは、コンテナのIOを制御する比率です。デフォルト値は500で、範囲は10から1000です。
docker run -it -m 500M --kernel-memory 50M --cpu-shares 512 --blkio-weight 400 --name ubuntu1 ubuntu bash
コンテナのcgroupを取得するには、次のようにします:
docker run -dt --rm denial sleep 1234 #Run a large sleep inside a Debian container
ps -ef | grep 1234 #Get info about the sleep process
ls -l /proc/<PID>/ns #Get the Group and the namespaces (some may be uniq to the hosts and some may be shred with it)
詳細については、次を確認してください:
Capabilities
Capabilitiesは、rootユーザーに許可される能力をより細かく制御することを可能にします。Dockerは、ユーザーの種類に関係なく、コンテナ内で実行できる操作を制限するためにLinuxカーネルの能力機能を使用します。
Dockerコンテナが実行されると、プロセスは隔離から脱出するために使用できる敏感な能力を放棄します。これは、プロセスが敏感なアクションを実行し、脱出できないことを保証しようとします:
Seccomp in Docker
これは、Dockerがコンテナ内で使用できるsyscallを制限することを可能にするセキュリティ機能です:
AppArmor in Docker
AppArmorは、コンテナを限られたリソースのセットに制限するためのカーネル拡張です。プログラムごとのプロファイルを持っています:
SELinux in Docker
- ラベリングシステム: SELinuxは、すべてのプロセスとファイルシステムオブジェクトに一意のラベルを割り当てます。
- ポリシーの強制: プロセスラベルがシステム内の他のラベルに対してどのアクションを実行できるかを定義するセキュリティポリシーを強制します。
- コンテナプロセスラベル: コンテナエンジンがコンテナプロセスを開始するとき、通常は制限されたSELinuxラベル、一般的に
container_tが割り当てられます。 - コンテナ内のファイルラベリング: コンテナ内のファイルは通常
container_file_tとしてラベル付けされます。 - ポリシールール: SELinuxポリシーは、
container_tラベルを持つプロセスがcontainer_file_tとしてラベル付けされたファイルとのみ相互作用(読み取り、書き込み、実行)できることを主に保証します。
このメカニズムにより、コンテナ内のプロセスが侵害された場合でも、対応するラベルを持つオブジェクトとのみ相互作用するように制限され、そうした侵害からの潜在的な損害が大幅に制限されます。
AuthZ & AuthN
Dockerでは、認可プラグインがセキュリティにおいて重要な役割を果たし、Dockerデーモンへのリクエストを許可またはブロックするかを決定します。この決定は、2つの重要なコンテキストを調べることによって行われます:
- 認証コンテキスト: これには、ユーザーが誰であるか、どのように認証されたかに関する包括的な情報が含まれます。
- コマンドコンテキスト: これには、行われているリクエストに関連するすべての重要なデータが含まれます。
これらのコンテキストは、認証されたユーザーからの正当なリクエストのみが処理されることを保証し、Docker操作のセキュリティを強化します。
AuthZ& AuthN - Docker Access Authorization Plugin
コンテナからのDoS
コンテナが使用できるリソースを適切に制限していない場合、侵害されたコンテナが実行されているホストにDoSを引き起こす可能性があります。
- CPU DoS
# stress-ng
sudo apt-get install -y stress-ng && stress-ng --vm 1 --vm-bytes 1G --verify -t 5m
# While loop
docker run -d --name malicious-container -c 512 busybox sh -c 'while true; do :; done'
- バンド幅DoS
nc -lvp 4444 >/dev/null & while true; do cat /dev/urandom | nc <target IP> 4444; done
興味深いDockerフラグ
–privilegedフラグ
次のページでは**--privilegedフラグが何を意味するか**を学ぶことができます:
–security-opt
no-new-privileges
攻撃者が低特権ユーザーとしてアクセスを得ることができるコンテナを実行している場合、誤って設定されたsuidバイナリがあると、攻撃者はそれを悪用し、コンテナ内で特権を昇格させる可能性があります。これにより、彼はコンテナから脱出できるかもしれません。
no-new-privilegesオプションを有効にしてコンテナを実行すると、この種の特権昇格を防ぐことができます。
docker run -it --security-opt=no-new-privileges:true nonewpriv
その他
#You can manually add/drop capabilities with
--cap-add
--cap-drop
# You can manually disable seccomp in docker with
--security-opt seccomp=unconfined
# You can manually disable seccomp in docker with
--security-opt apparmor=unconfined
# You can manually disable selinux in docker with
--security-opt label:disable
For more --security-opt options check: https://docs.docker.com/engine/reference/run/#security-configuration
その他のセキュリティ考慮事項
シークレットの管理: ベストプラクティス
シークレットをDockerイメージに直接埋め込んだり、環境変数を使用したりすることは避けることが重要です。これらの方法は、docker inspectやexecのようなコマンドを通じてコンテナにアクセスできる誰にでも機密情報を露出させてしまいます。
Dockerボリュームは、機密情報にアクセスするためのより安全な代替手段です。これらはメモリ内の一時ファイルシステムとして利用でき、docker inspectやログに関連するリスクを軽減します。ただし、rootユーザーやコンテナへのexecアクセスを持つユーザーは、依然としてシークレットにアクセスできる可能性があります。
Dockerシークレットは、機密情報を扱うためのさらに安全な方法を提供します。イメージビルドフェーズ中にシークレットが必要なインスタンスには、BuildKitがビルド時のシークレットをサポートし、ビルド速度を向上させ、追加機能を提供する効率的なソリューションを提供します。
BuildKitを活用するには、以下の3つの方法で有効化できます:
- 環境変数を通じて:
export DOCKER_BUILDKIT=1 - コマンドにプレフィックスを付けて:
DOCKER_BUILDKIT=1 docker build . - Docker設定でデフォルトで有効にする:
{ "features": { "buildkit": true } }、その後Dockerを再起動します。
BuildKitは、--secretオプションを使用してビルド時のシークレットを利用できるようにし、これらのシークレットがイメージビルドキャッシュや最終イメージに含まれないようにします。コマンドの例は次の通りです:
docker build --secret my_key=my_value ,src=path/to/my_secret_file .
実行中のコンテナに必要な秘密情報について、Docker Compose と Kubernetes は堅牢なソリューションを提供します。Docker Compose は、docker-compose.yml の例に示すように、秘密ファイルを指定するためにサービス定義内で secrets キーを利用します:
version: "3.7"
services:
my_service:
image: centos:7
entrypoint: "cat /run/secrets/my_secret"
secrets:
- my_secret
secrets:
my_secret:
file: ./my_secret_file.txt
この設定により、Docker Composeを使用してサービスを起動する際にシークレットを使用することができます。
Kubernetes環境では、シークレットがネイティブにサポートされており、Helm-Secretsのようなツールでさらに管理できます。Kubernetesのロールベースアクセス制御(RBAC)は、Docker Enterpriseと同様にシークレット管理のセキュリティを強化します。
gVisor
gVisorは、Goで書かれたアプリケーションカーネルで、Linuxシステムの表面の大部分を実装しています。アプリケーションとホストカーネルの間に隔離境界を提供するrunscというOpen Container Initiative (OCI)ランタイムを含んでいます。runscランタイムはDockerとKubernetesと統合されており、サンドボックス化されたコンテナを簡単に実行できます。
GitHub - google/gvisor: Application Kernel for Containers
Kata Containers
Kata Containersは、軽量の仮想マシンを使用して安全なコンテナランタイムを構築するために活動しているオープンソースコミュニティです。これにより、コンテナのように感じられ、動作しますが、ハードウェア仮想化技術を使用してより強力なワークロードの隔離を提供します。
Kata Containers - Open Source Container Runtime Software | Kata Containers
まとめのヒント
--privilegedフラグを使用したり、 Dockerソケットをコンテナ内にマウントしないでください。 Dockerソケットはコンテナを生成することを可能にするため、例えば--privilegedフラグを使用して別のコンテナを実行することでホストを完全に制御する簡単な方法です。- コンテナ内でrootとして実行しないでください。 異なるユーザーを使用し 、 ユーザー名前空間を使用してください。 コンテナ内のrootは、ユーザー名前空間で再マップされない限り、ホストのrootと同じです。主にLinuxの名前空間、能力、cgroupsによって軽く制限されています。
- すべての能力を削除 (
--cap-drop=all)し、必要なものだけを有効にしてください (--cap-add=...)。多くのワークロードは能力を必要とせず、それを追加すると潜在的な攻撃の範囲が広がります。 - “no-new-privileges”セキュリティオプションを使用してください 。 これにより、プロセスがsuidバイナリを通じてより多くの特権を得ることを防ぎます。
- コンテナに利用可能なリソースを制限してください。 リソース制限は、サービス拒否攻撃からマシンを保護できます。
- seccomp 、AppArmor (またはSELinux)プロファイルを調整して、コンテナに必要な最小限のアクションとシステムコールを制限してください。
- 公式のdockerイメージを使用し 、署名を要求してください 、またはそれに基づいて自分のものを構築してください。 バックドア付きのイメージを継承したり使用したりしないでください。ルートキーやパスフレーズは安全な場所に保管してください。DockerはUCPでキーを管理する計画を持っています。
- 定期的に イメージを再構築して、ホストとイメージにセキュリティパッチを適用してください。
- シークレットを賢く管理し、攻撃者がアクセスするのを難しくしてください。
- Dockerデーモンを公開する場合は、クライアントとサーバーの認証を使用してHTTPSを使用してください。
- Dockerfileでは、ADDの代わりにCOPYを優先してください。 ADDは自動的に圧縮ファイルを抽出し、URLからファイルをコピーできます。COPYにはこれらの機能がありません。可能な限りADDの使用を避け、リモートURLやZipファイルを通じた攻撃に対して脆弱にならないようにしてください。
- 各マイクロサービスに対して別々のコンテナを持ってください。
- コンテナ内にsshを置かないでください。 “docker exec”を使用してコンテナにsshできます。
- より小さなコンテナイメージを持ってください。
Dockerブレイクアウト / 特権昇格
もしあなたがdockerコンテナ内にいるか、dockerグループのユーザーにアクセスできる場合、脱出して特権を昇格させることを試みることができます:
Docker Breakout / Privilege Escalation
Docker認証プラグインバイパス
もしあなたがdockerソケットにアクセスできるか、dockerグループのユーザーにアクセスできるが、あなたの行動がdocker認証プラグインによって制限されている場合、バイパスできるか確認してください:
AuthZ& AuthN - Docker Access Authorization Plugin
Dockerの強化
- ツールdocker-bench-securityは、Dockerコンテナを本番環境で展開する際の一般的なベストプラクティスをチェックするスクリプトです。テストはすべて自動化されており、CIS Docker Benchmark v1.3.1に基づいています。
このツールは、dockerを実行しているホストまたは十分な特権を持つコンテナから実行する必要があります。READMEでの実行方法を確認してください: https://github.com/docker/docker-bench-security。
参考文献
- https://blog.trailofbits.com/2019/07/19/understanding-docker-container-escapes/
- https://twitter.com/_fel1x/status/1151487051986087936
- https://ajxchapman.github.io/containers/2020/11/19/privileged-container-escape.html
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-1overview/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-2docker-engine/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-3engine-access/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-4container-image/
- https://en.wikipedia.org/wiki/Linux_namespaces
- https://towardsdatascience.com/top-20-docker-security-tips-81c41dd06f57
- https://www.redhat.com/sysadmin/privileged-flag-container-engines
- https://docs.docker.com/engine/extend/plugins_authorization
- https://towardsdatascience.com/top-20-docker-security-tips-81c41dd06f57
- https://resources.experfy.com/bigdata-cloud/top-20-docker-security-tips/
Tip
AWSハッキングを学び、実践する:
GCPハッキングを学び、実践する:HackTricksをサポートする
- サブスクリプションプランを確認してください!
- **💬 Discordグループまたはテレグラムグループに参加するか、Twitter 🐦 @hacktricks_liveをフォローしてください。
- HackTricksおよびHackTricks CloudのGitHubリポジトリにPRを提出してハッキングトリックを共有してください。