Sécurité Docker
Tip
Apprenez et pratiquez le hacking AWS :
HackTricks Training AWS Red Team Expert (ARTE)
Apprenez et pratiquez le hacking GCP :HackTricks Training GCP Red Team Expert (GRTE)
HackTricks Training Azure Red Team Expert (AzRTE)
Soutenir HackTricks
- Vérifiez les plans d’abonnement !
- Rejoignez le 💬 groupe Discord ou le groupe telegram ou suivez-nous sur Twitter 🐦 @hacktricks_live.
- Partagez des astuces de hacking en soumettant des PR au HackTricks et HackTricks Cloud dépôts github.
Sécurité de base du moteur Docker
Le moteur Docker utilise les Namespaces et Cgroups du noyau Linux pour isoler les conteneurs, offrant une couche de sécurité de base. Une protection supplémentaire est fournie par le dropping de Capabilities, Seccomp, et SELinux/AppArmor, améliorant l’isolation des conteneurs. Un plugin d’authentification peut encore restreindre les actions des utilisateurs.
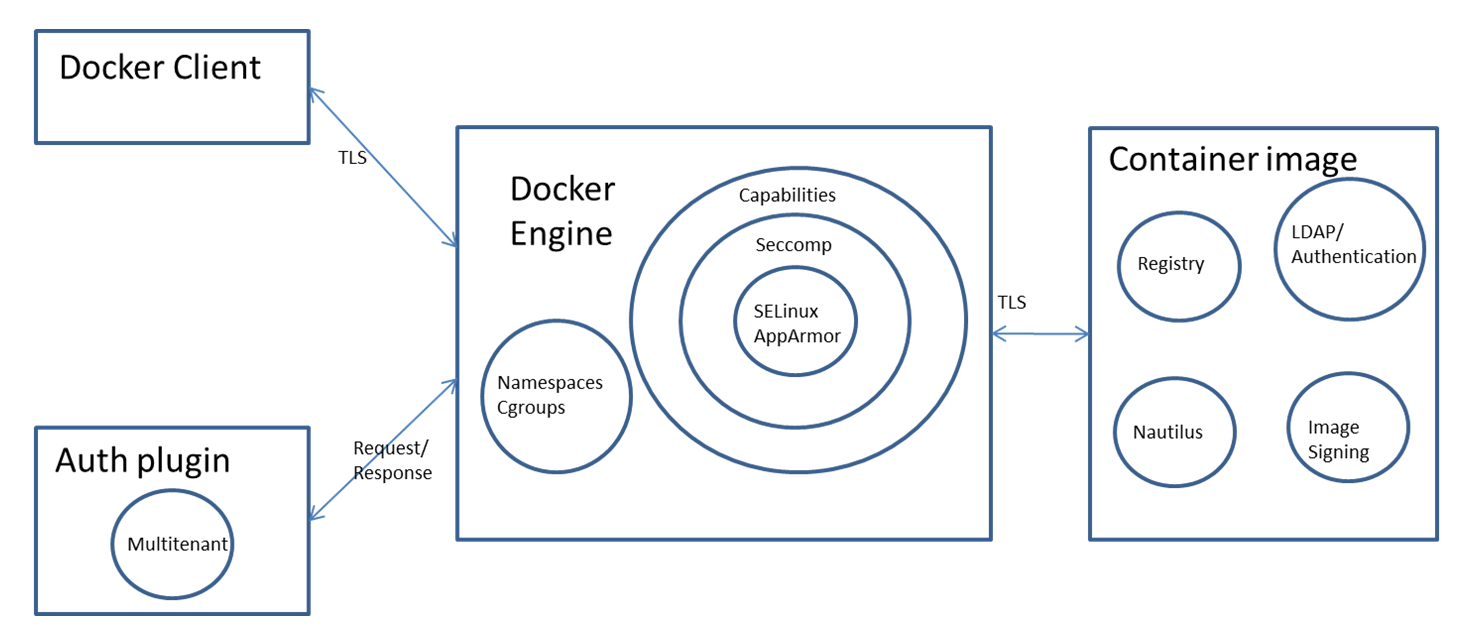
Accès sécurisé au moteur Docker
Le moteur Docker peut être accessible localement via un socket Unix ou à distance en utilisant HTTP. Pour un accès à distance, il est essentiel d’utiliser HTTPS et TLS pour garantir la confidentialité, l’intégrité et l’authentification.
Le moteur Docker, par défaut, écoute sur le socket Unix à unix:///var/run/docker.sock. Sur les systèmes Ubuntu, les options de démarrage de Docker sont définies dans /etc/default/docker. Pour activer l’accès à distance à l’API Docker et au client, exposez le démon Docker via un socket HTTP en ajoutant les paramètres suivants :
DOCKER_OPTS="-D -H unix:///var/run/docker.sock -H tcp://192.168.56.101:2376"
sudo service docker restart
Cependant, exposer le démon Docker via HTTP n’est pas recommandé en raison de préoccupations de sécurité. Il est conseillé de sécuriser les connexions en utilisant HTTPS. Il existe deux approches principales pour sécuriser la connexion :
- Le client vérifie l’identité du serveur.
- Le client et le serveur s’authentifient mutuellement l’identité de chacun.
Des certificats sont utilisés pour confirmer l’identité d’un serveur. Pour des exemples détaillés des deux méthodes, consultez ce guide.
Sécurité des images de conteneurs
Les images de conteneurs peuvent être stockées dans des dépôts privés ou publics. Docker propose plusieurs options de stockage pour les images de conteneurs :
- Docker Hub : Un service de registre public de Docker.
- Docker Registry : Un projet open-source permettant aux utilisateurs d’héberger leur propre registre.
- Docker Trusted Registry : L’offre de registre commercial de Docker, avec authentification des utilisateurs basée sur des rôles et intégration avec des services d’annuaire LDAP.
Analyse d’images
Les conteneurs peuvent avoir des vulnérabilités de sécurité soit à cause de l’image de base, soit à cause des logiciels installés sur l’image de base. Docker travaille sur un projet appelé Nautilus qui effectue une analyse de sécurité des conteneurs et répertorie les vulnérabilités. Nautilus fonctionne en comparant chaque couche d’image de conteneur avec un référentiel de vulnérabilités pour identifier les failles de sécurité.
Pour plus d’informations, lisez ceci.
docker scan
La commande docker scan vous permet de scanner des images Docker existantes en utilisant le nom ou l’ID de l’image. Par exemple, exécutez la commande suivante pour scanner l’image hello-world :
docker scan hello-world
Testing hello-world...
Organization: docker-desktop-test
Package manager: linux
Project name: docker-image|hello-world
Docker image: hello-world
Licenses: enabled
✓ Tested 0 dependencies for known issues, no vulnerable paths found.
Note that we do not currently have vulnerability data for your image.
trivy -q -f json <container_name>:<tag>
snyk container test <image> --json-file-output=<output file> --severity-threshold=high
clair-scanner -w example-alpine.yaml --ip YOUR_LOCAL_IP alpine:3.5
Signature d’image Docker
La signature d’image Docker garantit la sécurité et l’intégrité des images utilisées dans les conteneurs. Voici une explication condensée :
- Docker Content Trust utilise le projet Notary, basé sur The Update Framework (TUF), pour gérer la signature des images. Pour plus d’infos, voir Notary et TUF.
- Pour activer la confiance dans le contenu Docker, définissez
export DOCKER_CONTENT_TRUST=1. Cette fonctionnalité est désactivée par défaut dans Docker version 1.10 et ultérieure. - Avec cette fonctionnalité activée, seules les images signées peuvent être téléchargées. La première poussée d’image nécessite de définir des phrases de passe pour les clés racine et de balisage, Docker prenant également en charge Yubikey pour une sécurité renforcée. Plus de détails peuvent être trouvés ici.
- Tenter de tirer une image non signée avec la confiance dans le contenu activée entraîne une erreur “No trust data for latest”.
- Pour les poussées d’image après la première, Docker demande la phrase de passe de la clé du dépôt pour signer l’image.
Pour sauvegarder vos clés privées, utilisez la commande :
tar -zcvf private_keys_backup.tar.gz ~/.docker/trust/private
Lorsque vous changez d’hôtes Docker, il est nécessaire de déplacer les clés root et repository pour maintenir les opérations.
Fonctionnalités de Sécurité des Conteneurs
Résumé des Fonctionnalités de Sécurité des Conteneurs
Fonctionnalités Principales d’Isolation des Processus
Dans les environnements conteneurisés, l’isolation des projets et de leurs processus est primordiale pour la sécurité et la gestion des ressources. Voici une explication simplifiée des concepts clés :
Namespaces
- Objectif : Assurer l’isolation des ressources telles que les processus, le réseau et les systèmes de fichiers. Particulièrement dans Docker, les namespaces maintiennent les processus d’un conteneur séparés de l’hôte et des autres conteneurs.
- Utilisation de
unshare: La commandeunshare(ou l’appel système sous-jacent) est utilisée pour créer de nouveaux namespaces, fournissant une couche supplémentaire d’isolation. Cependant, bien que Kubernetes ne bloque pas cela par défaut, Docker le fait. - Limitation : La création de nouveaux namespaces ne permet pas à un processus de revenir aux namespaces par défaut de l’hôte. Pour pénétrer les namespaces de l’hôte, il faudrait généralement accéder au répertoire
/procde l’hôte, en utilisantnsenterpour l’entrée.
Groupes de Contrôle (CGroups)
- Fonction : Principalement utilisés pour allouer des ressources entre les processus.
- Aspect Sécuritaire : Les CGroups eux-mêmes n’offrent pas de sécurité d’isolation, sauf pour la fonctionnalité
release_agent, qui, si mal configurée, pourrait potentiellement être exploitée pour un accès non autorisé.
Abandon de Capacité
- Importance : C’est une fonctionnalité de sécurité cruciale pour l’isolation des processus.
- Fonctionnalité : Elle restreint les actions qu’un processus root peut effectuer en abandonnant certaines capacités. Même si un processus s’exécute avec des privilèges root, le manque de capacités nécessaires l’empêche d’exécuter des actions privilégiées, car les appels système échoueront en raison de permissions insuffisantes.
Voici les capabilités restantes après que le processus ait abandonné les autres :
Current: cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap=ep
Seccomp
Il est activé par défaut dans Docker. Il aide à limiter encore plus les syscalls que le processus peut appeler.
Le profil Seccomp par défaut de Docker peut être trouvé sur https://github.com/moby/moby/blob/master/profiles/seccomp/default.json
AppArmor
Docker a un modèle que vous pouvez activer : https://github.com/moby/moby/tree/master/profiles/apparmor
Cela permettra de réduire les capacités, les syscalls, l’accès aux fichiers et aux dossiers…
Namespaces
Les Namespaces sont une fonctionnalité du noyau Linux qui partitionne les ressources du noyau de sorte qu’un ensemble de processus voit un ensemble de ressources tandis qu’un autre ensemble de processus voit un ensemble différent de ressources. La fonctionnalité fonctionne en ayant le même namespace pour un ensemble de ressources et de processus, mais ces namespaces se réfèrent à des ressources distinctes. Les ressources peuvent exister dans plusieurs espaces.
Docker utilise les Namespaces du noyau Linux suivants pour atteindre l’isolation des conteneurs :
- pid namespace
- mount namespace
- network namespace
- ipc namespace
- UTS namespace
Pour plus d’informations sur les namespaces, consultez la page suivante :
cgroups
La fonctionnalité du noyau Linux cgroups fournit la capacité de restreindre les ressources comme le cpu, la mémoire, l’io, la bande passante réseau parmi un ensemble de processus. Docker permet de créer des conteneurs en utilisant la fonctionnalité cgroup qui permet le contrôle des ressources pour le conteneur spécifique.
Voici un conteneur créé avec une mémoire d’espace utilisateur limitée à 500m, une mémoire noyau limitée à 50m, une part de cpu à 512, un blkioweight à 400. La part de CPU est un ratio qui contrôle l’utilisation du CPU par le conteneur. Il a une valeur par défaut de 1024 et une plage entre 0 et 1024. Si trois conteneurs ont la même part de CPU de 1024, chaque conteneur peut prendre jusqu’à 33 % du CPU en cas de contention des ressources CPU. Le blkio-weight est un ratio qui contrôle l’IO du conteneur. Il a une valeur par défaut de 500 et une plage entre 10 et 1000.
docker run -it -m 500M --kernel-memory 50M --cpu-shares 512 --blkio-weight 400 --name ubuntu1 ubuntu bash
Pour obtenir le cgroup d’un conteneur, vous pouvez faire :
docker run -dt --rm denial sleep 1234 #Run a large sleep inside a Debian container
ps -ef | grep 1234 #Get info about the sleep process
ls -l /proc/<PID>/ns #Get the Group and the namespaces (some may be uniq to the hosts and some may be shred with it)
Pour plus d’informations, consultez :
Capacités
Les capacités permettent un contrôle plus fin des capacités qui peuvent être autorisées pour l’utilisateur root. Docker utilise la fonctionnalité de capacité du noyau Linux pour limiter les opérations qui peuvent être effectuées à l’intérieur d’un conteneur, indépendamment du type d’utilisateur.
Lorsqu’un conteneur docker est exécuté, le processus abandonne les capacités sensibles que le processus pourrait utiliser pour échapper à l’isolement. Cela essaie d’assurer que le processus ne pourra pas effectuer d’actions sensibles et s’échapper :
Seccomp dans Docker
C’est une fonctionnalité de sécurité qui permet à Docker de limiter les syscalls qui peuvent être utilisés à l’intérieur du conteneur :
AppArmor dans Docker
AppArmor est une amélioration du noyau pour confiner les conteneurs à un ensemble limité de ressources avec des profils par programme :
SELinux dans Docker
- Système de Labeling : SELinux attribue un label unique à chaque processus et objet de système de fichiers.
- Application des Politiques : Il applique des politiques de sécurité qui définissent quelles actions un label de processus peut effectuer sur d’autres labels au sein du système.
- Labels des Processus de Conteneur : Lorsque les moteurs de conteneur initient des processus de conteneur, ils se voient généralement attribuer un label SELinux confiné, communément
container_t. - Labeling des Fichiers dans les Conteneurs : Les fichiers à l’intérieur du conteneur sont généralement étiquetés comme
container_file_t. - Règles de Politique : La politique SELinux garantit principalement que les processus avec le label
container_tne peuvent interagir (lire, écrire, exécuter) qu’avec des fichiers étiquetés commecontainer_file_t.
Ce mécanisme garantit que même si un processus à l’intérieur d’un conteneur est compromis, il est confiné à interagir uniquement avec des objets ayant les labels correspondants, limitant considérablement les dommages potentiels résultant de tels compromis.
AuthZ & AuthN
Dans Docker, un plugin d’autorisation joue un rôle crucial dans la sécurité en décidant d’autoriser ou de bloquer les demandes au démon Docker. Cette décision est prise en examinant deux contextes clés :
- Contexte d’Authentification : Cela inclut des informations complètes sur l’utilisateur, telles que qui ils sont et comment ils se sont authentifiés.
- Contexte de Commande : Cela comprend toutes les données pertinentes liées à la demande en cours.
Ces contextes aident à garantir que seules les demandes légitimes d’utilisateurs authentifiés sont traitées, renforçant la sécurité des opérations Docker.
AuthZ& AuthN - Docker Access Authorization Plugin
DoS depuis un conteneur
Si vous ne limitez pas correctement les ressources qu’un conteneur peut utiliser, un conteneur compromis pourrait provoquer un DoS sur l’hôte où il s’exécute.
- DoS CPU
# stress-ng
sudo apt-get install -y stress-ng && stress-ng --vm 1 --vm-bytes 1G --verify -t 5m
# While loop
docker run -d --name malicious-container -c 512 busybox sh -c 'while true; do :; done'
- Bandwidth DoS
nc -lvp 4444 >/dev/null & while true; do cat /dev/urandom | nc <target IP> 4444; done
Drapeaux Docker intéressants
Drapeau –privileged
Dans la page suivante, vous pouvez apprendre ce que signifie le drapeau --privileged :
–security-opt
no-new-privileges
Si vous exécutez un conteneur où un attaquant parvient à accéder en tant qu’utilisateur à faible privilège. Si vous avez un binaire suid mal configuré, l’attaquant peut en abuser et escalader les privilèges à l’intérieur du conteneur. Ce qui peut lui permettre d’en sortir.
Exécuter le conteneur avec l’option no-new-privileges activée préventera ce type d’escalade de privilèges.
docker run -it --security-opt=no-new-privileges:true nonewpriv
Autre
#You can manually add/drop capabilities with
--cap-add
--cap-drop
# You can manually disable seccomp in docker with
--security-opt seccomp=unconfined
# You can manually disable seccomp in docker with
--security-opt apparmor=unconfined
# You can manually disable selinux in docker with
--security-opt label:disable
Pour plus d’options --security-opt, consultez : https://docs.docker.com/engine/reference/run/#security-configuration
Autres considérations de sécurité
Gestion des secrets : Meilleures pratiques
Il est crucial d’éviter d’incorporer des secrets directement dans les images Docker ou d’utiliser des variables d’environnement, car ces méthodes exposent vos informations sensibles à quiconque ayant accès au conteneur via des commandes comme docker inspect ou exec.
Les volumes Docker sont une alternative plus sûre, recommandée pour accéder à des informations sensibles. Ils peuvent être utilisés comme un système de fichiers temporaire en mémoire, atténuant les risques associés à docker inspect et à la journalisation. Cependant, les utilisateurs root et ceux ayant accès à exec dans le conteneur pourraient toujours accéder aux secrets.
Les secrets Docker offrent une méthode encore plus sécurisée pour gérer des informations sensibles. Pour les instances nécessitant des secrets pendant la phase de construction de l’image, BuildKit présente une solution efficace avec prise en charge des secrets au moment de la construction, améliorant la vitesse de construction et fournissant des fonctionnalités supplémentaires.
Pour tirer parti de BuildKit, il peut être activé de trois manières :
- Via une variable d’environnement :
export DOCKER_BUILDKIT=1 - En préfixant les commandes :
DOCKER_BUILDKIT=1 docker build . - En l’activant par défaut dans la configuration Docker :
{ "features": { "buildkit": true } }, suivi d’un redémarrage de Docker.
BuildKit permet l’utilisation de secrets au moment de la construction avec l’option --secret, garantissant que ces secrets ne sont pas inclus dans le cache de construction de l’image ou l’image finale, en utilisant une commande comme :
docker build --secret my_key=my_value ,src=path/to/my_secret_file .
Pour les secrets nécessaires dans un conteneur en cours d’exécution, Docker Compose et Kubernetes offrent des solutions robustes. Docker Compose utilise une clé secrets dans la définition du service pour spécifier des fichiers secrets, comme montré dans un exemple de docker-compose.yml :
version: "3.7"
services:
my_service:
image: centos:7
entrypoint: "cat /run/secrets/my_secret"
secrets:
- my_secret
secrets:
my_secret:
file: ./my_secret_file.txt
Cette configuration permet l’utilisation de secrets lors du démarrage de services avec Docker Compose.
Dans les environnements Kubernetes, les secrets sont pris en charge nativement et peuvent être gérés davantage avec des outils comme Helm-Secrets. Les contrôles d’accès basés sur les rôles (RBAC) de Kubernetes améliorent la sécurité de la gestion des secrets, similaire à Docker Enterprise.
gVisor
gVisor est un noyau d’application, écrit en Go, qui implémente une partie substantielle de la surface système Linux. Il inclut un runtime Open Container Initiative (OCI) appelé runsc qui fournit une barrière d’isolation entre l’application et le noyau hôte. Le runtime runsc s’intègre avec Docker et Kubernetes, facilitant l’exécution de conteneurs en bac à sable.
GitHub - google/gvisor: Application Kernel for Containers
Kata Containers
Kata Containers est une communauté open source travaillant à construire un runtime de conteneur sécurisé avec des machines virtuelles légères qui se comportent et fonctionnent comme des conteneurs, mais fournissent une isolation de charge de travail plus forte en utilisant la technologie de virtualisation matérielle comme deuxième couche de défense.
Kata Containers - Open Source Container Runtime Software | Kata Containers
Résumé des conseils
- N’utilisez pas le drapeau
--privilegedou ne montez pas un socket Docker à l’intérieur du conteneur. Le socket Docker permet de créer des conteneurs, ce qui est un moyen facile de prendre le contrôle total de l’hôte, par exemple, en exécutant un autre conteneur avec le drapeau--privileged. - Ne travaillez pas en tant que root à l’intérieur du conteneur. Utilisez un utilisateur différent et des espaces de noms utilisateur. Le root dans le conteneur est le même que sur l’hôte, sauf s’il est remappé avec des espaces de noms utilisateur. Il est seulement légèrement restreint par, principalement, les espaces de noms Linux, les capacités et les cgroups.
- Supprimez toutes les capacités (
--cap-drop=all) et activez uniquement celles qui sont nécessaires (--cap-add=...). Beaucoup de charges de travail n’ont pas besoin de capacités et les ajouter augmente le champ d’une attaque potentielle. - Utilisez l’option de sécurité “no-new-privileges” pour empêcher les processus d’acquérir plus de privilèges, par exemple via des binaires suid.
- Limitez les ressources disponibles pour le conteneur. Les limites de ressources peuvent protéger la machine contre les attaques par déni de service.
- Ajustez seccomp, AppArmor (ou SELinux) les profils pour restreindre les actions et les syscalls disponibles pour le conteneur au minimum requis.
- Utilisez des images Docker officielles et exigez des signatures ou construisez les vôtres à partir de celles-ci. N’héritez pas ou n’utilisez pas d’images backdoorées. Conservez également les clés root et les phrases de passe dans un endroit sûr. Docker prévoit de gérer les clés avec UCP.
- Reconstruisez régulièrement vos images pour appliquer des correctifs de sécurité à l’hôte et aux images.
- Gérez vos secrets avec sagesse afin qu’il soit difficile pour l’attaquant d’y accéder.
- Si vous exposez le démon Docker, utilisez HTTPS avec authentification client et serveur.
- Dans votre Dockerfile, privilégiez COPY au lieu de ADD. ADD extrait automatiquement les fichiers compressés et peut copier des fichiers à partir d’URL. COPY n’a pas ces capacités. Évitez d’utiliser ADD autant que possible pour ne pas être vulnérable aux attaques via des URL distantes et des fichiers Zip.
- Ayez des conteneurs séparés pour chaque micro-service.
- Ne mettez pas ssh à l’intérieur du conteneur, “docker exec” peut être utilisé pour ssh au conteneur.
- Ayez des images de conteneur plus petites.
Docker Breakout / Escalade de privilèges
Si vous êtes à l’intérieur d’un conteneur Docker ou si vous avez accès à un utilisateur dans le groupe docker, vous pourriez essayer de vous échapper et d’escalader les privilèges :
Docker Breakout / Privilege Escalation
Contournement du plugin d’authentification Docker
Si vous avez accès au socket Docker ou si vous avez accès à un utilisateur dans le groupe docker mais que vos actions sont limitées par un plugin d’authentification Docker, vérifiez si vous pouvez le contourner :
AuthZ& AuthN - Docker Access Authorization Plugin
Renforcement de Docker
- L’outil docker-bench-security est un script qui vérifie des dizaines de meilleures pratiques courantes concernant le déploiement de conteneurs Docker en production. Les tests sont tous automatisés et sont basés sur le CIS Docker Benchmark v1.3.1.
Vous devez exécuter l’outil depuis l’hôte exécutant Docker ou depuis un conteneur avec suffisamment de privilèges. Découvrez comment l’exécuter dans le README : https://github.com/docker/docker-bench-security.
Références
- https://blog.trailofbits.com/2019/07/19/understanding-docker-container-escapes/
- https://twitter.com/_fel1x/status/1151487051986087936
- https://ajxchapman.github.io/containers/2020/11/19/privileged-container-escape.html
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-1overview/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-2docker-engine/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-3engine-access/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-4container-image/
- https://en.wikipedia.org/wiki/Linux_namespaces
- https://towardsdatascience.com/top-20-docker-security-tips-81c41dd06f57
- https://www.redhat.com/sysadmin/privileged-flag-container-engines
- https://docs.docker.com/engine/extend/plugins_authorization
- https://towardsdatascience.com/top-20-docker-security-tips-81c41dd06f57
- https://resources.experfy.com/bigdata-cloud/top-20-docker-security-tips/
Tip
Apprenez et pratiquez le hacking AWS :
Apprenez et pratiquez le hacking GCP :Soutenir HackTricks
- Vérifiez les plans d’abonnement !
- Rejoignez le 💬 groupe Discord ou le groupe telegram ou suivez-nous sur Twitter 🐦 @hacktricks_live.
- Partagez des astuces de hacking en soumettant des PR au HackTricks et HackTricks Cloud dépôts github.